














はじめに
最近、X や YouTube、note などでよく見かける投稿があります。
それは「ChatGPT に聞いてみたら、こんな答えが返ってきました」という形式のものです。
AI の返答は一見すると整っていて読みやすく、断定的な言い回しが多いため、つい「正しそうだ」と思ってしまいます。
しかし、そのまま引用して拡散してしまうと、意図せず誤情報を広げてしまうリスクがあります。
この記事では、以下の3点を整理していきます。
- 人が AI の返答を“正しい情報”と誤解しやすい心理的な理由
- 「AI が言ったこと」をそのままソースにする危うさ
- 拡散前にできる簡単な確認のステップ
AI を否定するのではなく、**「正しく使うために注意すべき点」**を共有することが目的です。
人がAIを“信じてしまう”心理の罠
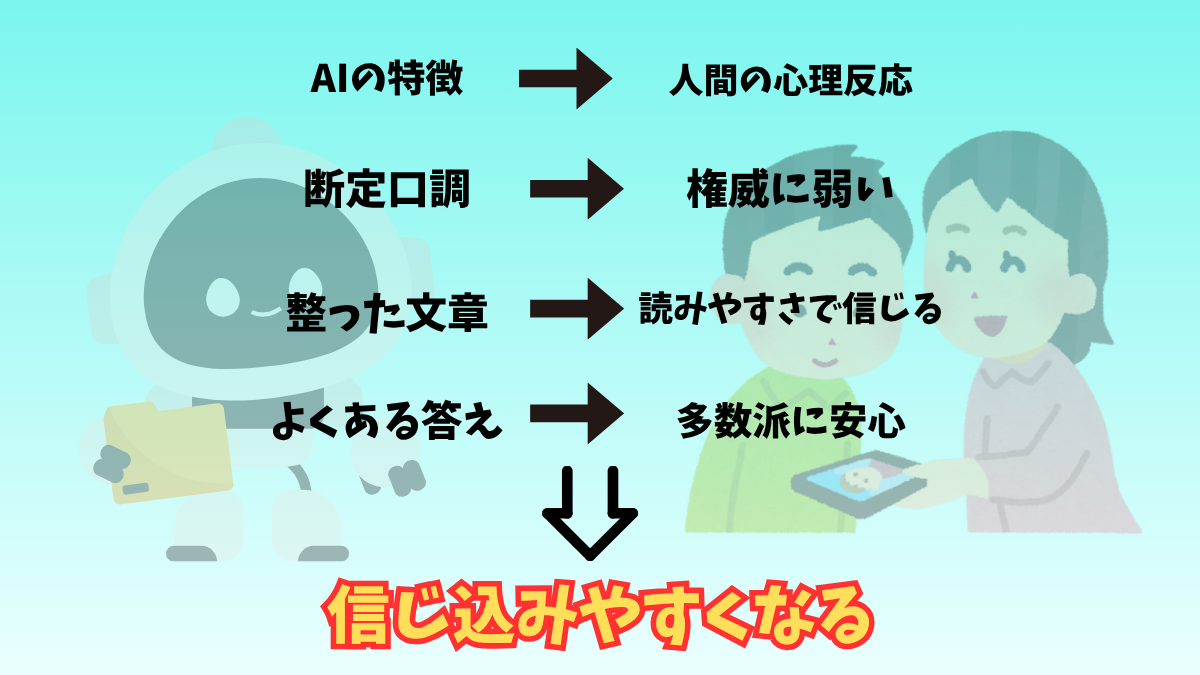
「ChatGPTがこう答えたから正しいだろう」──そう思ってしまうのは、人間の心理に仕掛けられた“罠”があるからです。心理学や行動経済学の研究からも、そのメカニズムは説明できます。
1. 断定口調は“権威”に見える
AIは「〜です」「〜になります」と断定口調で答えます。
これは心理学でいう 「権威効果(authority bias)」。
人は自信を持って断言されると、それが正しいと感じやすいのです。
例:
「富士山は日本で最も高い山で、標高は3,776mです。」
──このように数字を添えて断言されると、たとえ誤りが含まれていても信じやすくなります。
2. 整った文章は“信頼感”を演出する
AIの返答は接続詞や段落がきれいに整っており、読みやすい構成になっています。
これは 「流暢性の効果(fluency effect)」 と呼ばれるもので、人は理解しやすい文章を「正しい情報」と錯覚しやすいことが研究で知られています(Alter & Oppenheimer, 2009)。
例:
「NISAには毎年一定の非課税投資枠があります。一般NISAでは年間120万円、つみたてNISAでは年間40万円までの投資が可能です。」
──文章として整っているため信じたくなりますが、実際には制度改正で数字が変わっています。
3. “よくある答え”が安心を呼ぶ
AIは学習データの傾向から「多数派が言っていること」を優先します。
これは社会心理学でいう 「バンドワゴン効果(bandwagon effect)」。
「みんながそう言っている」という情報は、正確さとは別に「安心感」を与えてしまうのです。
例:
「日本の観光地ランキング」→ 東京タワー、富士山、清水寺。
──確かに有名ですが、最新の人気調査に基づいているわけではありません。
このように、権威効果・流暢性効果・バンドワゴン効果が重なることで、AIの返答は非常に「正しそう」に見えてしまいます。
しかし、その“正しそう”に油断すると、誤情報をそのまま信じ込み、拡散してしまうのです。
実際にこんな“誤答”がある──そしてなぜ起きるのか
AIの返答をそのままソースにしてはいけない理由は、単に人間が錯覚しやすいからだけではありません。
AIそのものの構造的な限界によって、実際に誤答が起きるからです。
ここでは3つの典型例を見てみましょう。
1. 制度やお金に関する誤情報
例:「NISAの投資枠は年間120万円です」
実際には、2024年の制度改正で大きく変更され、投資枠は拡大されています。
なぜ起きるのか?
AIには「時間の感覚」がありません。
過去の学習データをもとに文章を生成しているため、古い情報と新しい情報を区別できないのです。
その結果、「2025年のイベント内容を知りたい」と質問しても、2024年の情報を答えてしまうといった混同が起こります。
2. 名言や著者の取り違え
例:「村上春樹の『走れメロス』は〜」
実際には太宰治の作品です。
なぜ起きるのか?
これは 認知心理学 でいう 「ソースモニタリングエラー(source monitoring error)」 に似ています。
人間は「どこで得たか」という出典を間違えて記憶してしまうことが多いのです。
「友達に聞いたと思っていたら、実はテレビで見ただけだった」というような記憶の錯誤が典型です(Johnson, Hashtroudi, & Lindsay, 1993)。
AIもまた、情報を「パターン」として扱うだけで出典を管理していません。
そのため「走れメロス」「日本文学」「著名作家」といった関連語を同時に呼び出すと、著者を誤って結びつけてしまうのです。
3. 雑学や一般知識のズレ
例:「富士山は日本で二番目に高い山です」
もちろん実際には日本一の高さを誇る山です。
なぜ起きるのか?
AIは正確さよりも「もっともらしい答え」を優先して生成します。
つまり、確率的にそれっぽい単語や数字を並べているにすぎません。
しかも「数字+断定」という形式は、人間に強い信頼感を与えてしまいます。
スタンフォード大学の研究でも、数字を伴う誤情報は、人の記憶に強く残りやすいことが示されています。
このように、AIの誤答には必ず「なぜそうなるか」という構造的な理由があります。
だからこそ「ChatGPTに聞いたから安心」ではなく、自分で裏取りをする姿勢が欠かせないのです。
👉 次章では、「AIが言ったから仕方ない」という言い訳が通用しない理由──つまり情報発信の責任について考えていきます。
「AIが言った」は免罪符にならない
SNSやブログで「ChatGPTがこう答えていた」と投稿する人は増えています。
しかし、その返答をそのまま拡散した瞬間から、責任はAIではなく“発信者”に移るのです。
1. 実際に危険な投稿パターン
❌ パターン①:医療情報をそのまま引用
「ChatGPTに聞いたら“この薬は副作用がほとんどない”って答えてました!」
→ 医薬品の安全性は専門的な一次情報(厚生労働省・製薬会社の添付文書)を確認する必要があります。誤情報を信じてしまえば健康被害につながります。
❌ パターン②:お金や投資の誤情報
「AIに聞いたら“つみたてNISAの年間投資枠は40万円です”と出ました」
→ 実際には2024年から制度が改正され、情報が古いまま拡散すると「正しい投資判断」を妨げてしまいます。金銭的損失に直結する分野は特にリスクが高いです。
❌ パターン③:制度・法律の誤案内
「障害年金は“誰でも申請すれば通ります”ってAIが言ってました」
→ 現実には厳格な審査基準があり、要件を満たさなければ支給されません。このような誤情報は、制度利用を考える人を誤導し、混乱を招きます。
2. 責任回避バイアスの罠
心理学では、自分の行動の責任を外部要因に押し付ける傾向を 「自己奉仕バイアス(self-serving bias)」 と呼びます。
「AIが答えたんだから仕方ない」と考えるのはまさにこのバイアスですが、拡散した時点で**読者にとっては“あなたの情報”**なのです。
3. 法律的にも免責されない
- 誤情報を元に健康被害 → 医療分野なら重大なリスク
- 投資や税制で誤情報を拡散 → 損害賠償の可能性
- 制度や法律の誤情報 → 公的機関の信用失墜に関わる
「AIが言った」は法的な責任を免れる理由にはなりません。
4. 透明性を担保する工夫
- AI返答をそのまま“事実”として出さない
- 使うなら「AIの返答例」であることを明示
- 必ず公式ソース(省庁・企業・研究機関)の情報で裏取りする
AIは便利ですが、「ソース」として扱うのは危険です。
拡散の責任はAIではなく、常に人間にあります。
👉 次章では、誤情報拡散を防ぐためにできる簡単なセルフチェックの方法を紹介します。
拡散前にできるセルフチェック
AIの返答をそのまま投稿する前に、ほんの少し確認するだけで誤情報拡散のリスクは大きく減らせます。
以下の3つを意識するだけで、AIの情報を「正しく使える人」と「振り回される人」の差がはっきり分かれます。
✅ チェック1:出典を確認したか?
AIの答えには、出典や根拠が書かれていないことが多い。
だからこそ、自分で「情報の源」を追いかける必要があります。
- 公式サイト(省庁・大学・企業公式)を確認する
- 原典(法律条文・研究論文・一次統計)にあたる
- 「この情報を人に勧められるか?」という観点で裏取りする
これを怠ると、もっともらしい“嘘”を自分の名前で広めてしまう危険があります。
✅ チェック2:複数ソースでクロスチェックしたか?
AIが答えたことを他の情報源と照らし合わせるのは必須です。
- 検索エンジンで同じテーマを調べる
- 複数のニュース記事・書籍・論文と比較する
- 自分の知識や経験と突き合わせて違和感がないか確認する
心理学では「確証バイアス」といって、自分が信じたい情報ばかり選んでしまう傾向があります。
だからこそ「AIが出した一つの答え」を鵜呑みにせず、意図的に他の視点を探すことが大切です。
✅ チェック3:表現を“自分の言葉”に変えたか?
AIの返答をコピペするのではなく、必ず自分の言葉に置き換えて投稿する。
これには2つの効果があります。
- 自分で理解できていない部分に気づける
- 読者に「情報」ではなく「あなたの解釈」を届けられる
もし「自分の言葉で言い換えられない」なら、それはまだ裏取りが足りていないサインです。
💡 ここで大切な視点
よく「AIは誰でも専門家にする」と言われます。
しかし、正確にはそれは違います。
AIは 「普通の人」を専門家にする魔法の杖ではありません。
むしろ、「並みの専門家」を一流に押し上げる力 を持っているのです。
- 普通の人は、AIの答えが正しいかどうか判断できない → 誤情報をそのまま広めてしまう
- 並みの専門家は、基礎知識と経験を持っている → AIの答えを検証し、活かせる
だからこそ、この「セルフチェック3つ」を習慣化できる人は、AIを単なる便利ツールではなく、**自分を一流に近づける“加速装置”**として使えるのです。
まとめ──AIを“ソース”ではなく“相棒”に
AIの返答は整っていて断定的だから、人はつい「正しそう」と思ってしまいます。
しかし実際には、権威効果・流暢性効果・バンドワゴン効果といった心理的罠が働き、誤情報を信じやすい仕組みがあります。
さらに、医療・お金・制度などの分野では、AIの誤答をそのまま拡散すると深刻なトラブルにつながります。
「AIが言ったから」は免罪符にはならず、責任はあくまで拡散した人間にあります。
そこで重要になるのが、次のセルフチェックです。
- 出典を確認する(一次情報にあたる)
- 複数ソースで照らし合わせる(確証バイアスに抗う)
- 自分の言葉で言い換える(理解度と責任を可視化する)
この3つを習慣にするだけで、あなたの発信は格段に信頼性を増します。
AIがもたらすもの

よく「AIは誰でも専門家にする」と言われますが、正しくは少し違います。
AIは普通の人を専門家にする魔法の杖ではありません。
AIは、すでに基礎を持つ“並みの専門家”を“一流の専門家”へと押し上げる力を持っています。
つまり、AIを正しく活用できるかどうかは、私たちの“姿勢”にかかっているのです。
AIをソースではなく、考えるための相棒として扱う。
そのスタンスを持つことで、誤情報を拡散するリスクを避けつつ、AIの可能性を最大限に引き出せます。
「ChatGPTがこう答えた」と投稿する前に、ほんの少し立ち止まって確認してみましょう。
その一手間が、あなたを“AIに振り回される人”から“AIを武器にできる人”へ変える第一歩になります。



コメント